Analýza indexace – Sběr URL adres ze sitemapy

V minulých článcích jste se dozvěděli, jak získat seznam stránek, které jsou indexované na Googlu a seznam stránek, které jsou indexované na Seznamu. Ještě, než začneme analyzovat, kde máme v indexaci mezery, je třeba získat sadu URL stránek, se kterou indexované stránky budeme porovnávat. Tato URL pro naše účely budeme čerpat ze dvou zdrojů: ze souboru sitemap a z „crawlu“. V tomto článku se dozvíte, jak lokalizovat soubor sitemap.xml a jak z něj jednoduše vytáhnout všechna URL stránek.
Co je sitemap a jak pomůže mému SEO?
Soubor sitemap.xml je (měl by být) seznam všech URL, které chceme mít indexované. Zpravidla v něm nenajdeme stránky jako jsou obchodní podmínky, košík a stránky, které jsou vyloučeny v souboru robots.txt (pokud je správně strukturován).
Mapa stránek tak usnadňuje robotům vyhledávačů procházení URL a tím pádem i zvyšuje šanci, že tyto URL budou indexované, optimalizace pro vyhledávače se dá dělat většinou jen pro stránky, které jsou ve vyhledávačích dohledatelné.

Kde soubor sitemap najdu a kde by měl být?
Nejčastěji sitemapu najdete na adrese www.vasweb.cz/sitemap.xml. Existují ale výjimky, kdy má soubor jiný název.
Aby soubor sitemap mohl procházet SeznamBot, je třeba na něj mít umístěný odkaz v souboru robots.txt (najdete na adrese www.vasweb.cz/robots.txt). Odkaz na sitemap nicméně využívá i Google.
Pro GoogleBota je dále vhodné mít odkaz na soubor sitemap vložený i do SearchConsole.
Sitemap
Po úspěšné lokalizaci byste se měli dostat na adresu, jejíž obsah vypadá nějak takhle:

Teď jenom z tama dostat ty URL adresy  Naštěstí to není vůbec složité a existuje spousta způsobů, jak toho docílit.
Naštěstí to není vůbec složité a existuje spousta způsobů, jak toho docílit.
Způsob 1 | Tabulkový editor
Můžete si pomocí klávesových zkratek Ctrl + A & Ctrl + C označit celý obsah souboru sitemap, který si pak vložíte do tabulkového editoru. Na první řádek byste pak aplikovali filtr „Text contains“ a jako value byste vložili třeba „http“. Výsledný mišmaš by vypadal asi takhle:
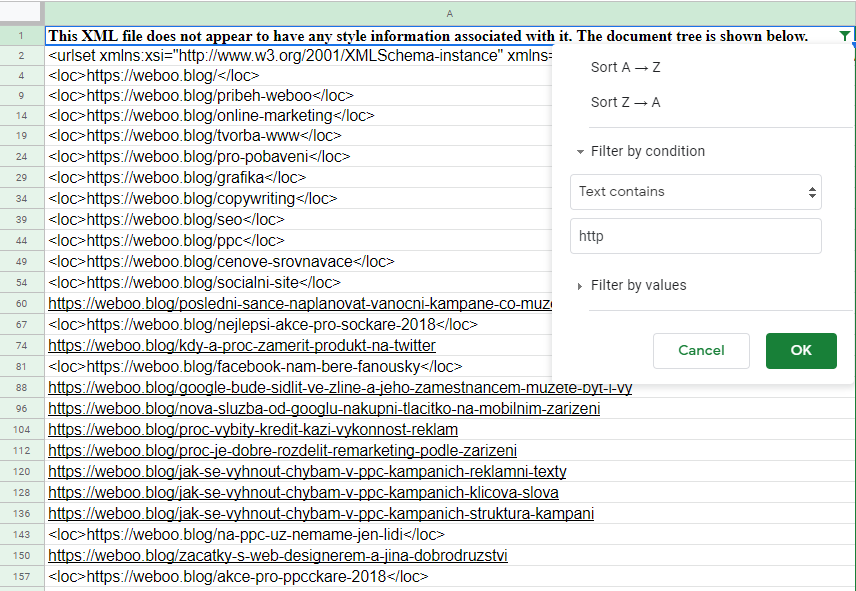
Neměl by být problém si pomocí „Hledat a nahradit“ vymazat všechny ty značky <loc> a dostat tak očištěnou sadu URL adres.

Způsob 2 | Externí služba
Existuje spousta nástrojů, které zpracují sitemap se stejným (možná o trochu rychlejším) výsledkem – „vyplivnou“ všechny URL adresy a můžete vesele kopírovat.
Stejně tak dobře funguje jakýkoliv převaděč z XML do CSV.
Tento způsob je o něco lepší, ale pořád nám u většiny takových nástrojů zůstávají data, která pro tuto chvíli nepotřebujeme a opět bychom museli je museli čistit o zbytečné sloupce. K tomu všemu ještě ta otrava hledání takové stránky 

Způsob 3 | Záložka v prohlížeči
Nej, nej, nej způsob. Nic rychlejšího snad ani neexistuje a existovat nemůže.
Stačí označit následující skript a přetáhnout jej mezi záložky v prohlížeči. Odteď kdykoliv, kdy budete mít otevřenou sitemapu, jste od extrakce všech URL ze sitemap jen jeden klik na záložku daleko. Vyzkoušejte si to
javascript:var a = document.getElementsByTagName('loc'), arr = '';for(var i=0; i<a.length; i++) arr +=('<div>' + a[i].textContent + '</div>');//Sitemap_by_Weboo
V příštím článku se budu věnovat tomu, jak dostat další seznam URL pomocí „crawlingu“. A nakonec to všechno splácneme dohromady a budeme mít hotovu základní analýzu indexace. Netrpělivci již teď můžou využít nástrojů jako je MarketingMiner nebo Collabim.

Bc. ADAM TELIČKA
SEO mág Adam je kromě optimalizace pro vyhledávače šikovný textař, e-mail markeťák, linkbuilder a specialista na gramatické oříšky.
Email: Tato e-mailová adresa je chráněna před spamboty. Pro její zobrazení musíte mít povolen Javascript.
