Analýza indexace – Scrape SERPu Seznamu

Vyhledáváte na Seznamu? Že ne? A znáte alespoň někoho kdo na Seznamu vyhledává? Já taky ne. Přesto je 14 % všech dotazů na českém trhu vyhledávačů položeno právě přes Seznam (zdroj tady). Pro některé množiny klíčových slov to může být i více. A to znamená, že Seznam pořád nemůžeme úplně vyloučit z SEO prací. Ne, že by se každá stránka měla optimalizovat nadvakrát, ale minimálně bychom se mohli ujistit, že jsou naše ultra vybroušené stránky vůbec dohledatelné. V minulém článku jsem popsal, jak rychle získat Googlem indexovaná URL. Teď se teda koukneme na zub Seznamu.
Pzn.: V současnosti lze, nejspíš kvůli Captche ve vyhledávání, scrapovat pouze prvních 30 stran vyhledávání. Řešením je buďto analýzu rozkouskovat nebo zvětšit delay ve skriptu.
Stejně jako u minulého článku podotýkám, že jsou supr žůžo nástroje, které zjistí stav indexace sady URL za pár vteřin. Na SEO restartu 2018 nicméně pánové Kirschner a Vondrášek (kteří se podílí na vývoji Seznamu, jakožto vyhledávače) vybízeli, ať se někdy podíváme i na poslední stránku Seznamu, že budeme překvapeni. Tentokrát nemám žádný kouzelný bookmarklet, takže budeme muset klikat víc, než dvakrát.
Co je k tomu teda potřeba?
Pár základních věcí, kterými by měl (kdyžtak se neuraž) disponovat každý, kdo se proklamuje za SEO specialistu.
- Excel (nepovinné)
- Open Refine (pokud nemám, stáhnu tady –> http://openrefine.org/download.html)
Tip: Pokud OpenRefine nejede, je možné, že nemáte nainstalovanou Javu. Stáhnete kdyžtak tady: https://java.com/en/download/)
Krok 1 – Příprava vstupních dat
Jakmile víme, pro jaký dotaz chceme zjistit výsledky, tak jej dostaneme do následujícího tabulkového tvaru:
| Dotaz | x | Stránka |
| site:domena.cz | 0 | 1 |
| site:domena.cz | 10 | 2 |
| site:domena.cz | 20 | 3 |
| site:domena.cz | 30 | 4 |
Do sloupce „Stránka“ vložte čísla stránek, které chcete skrejpovat, nejlépe až právě po tu poslední. Sloupec „x“ je vlastně jednoduchý vzoreček ve tvaru „stránka x 10 - 10“. Případně pro tvorbu této tabulky můžete využít tento excel s makrama, se kterým se nemůžete seknout.
NADUPANEJ EXCEL S MAKRAMA KE STAŽENÍ
Jak s tímto souborem pracovat?
- Otevřeme soubor
- Ujistíme se, že jsme na Listu 1
- Klikneme na „Povolit úpravy“ & „Povolit obsah“ ve žluté vrchní liště
- Nasypeme klíčová slova / site:doména.cz do řádků
- Nastavíme počet požadovaných stran stran (Pzn. V souboru je sice nastavený cap na 10 stránek, ale kdokoliv, kdo s Excelem dělal déle, než 5 minut, si to zvládne upravit ;) )
- Klik na „Spustit“
Pro jistotu přikládám obrázkový návod. Grafik má sice pořád dovolenou, ale já to stejně umím nejlíp.
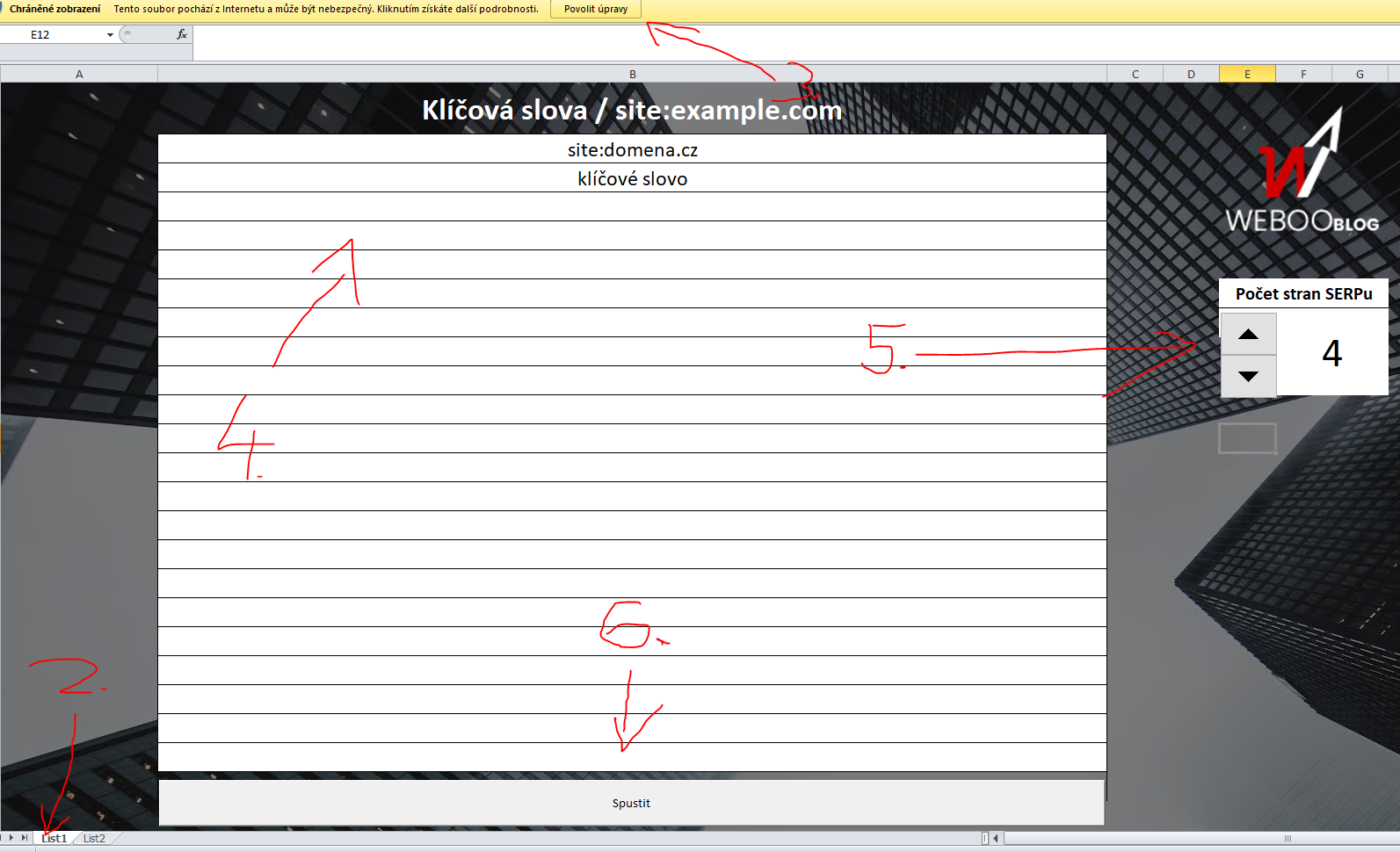
Hotovo? Oukej, mělo by nám vyjet něco takového:
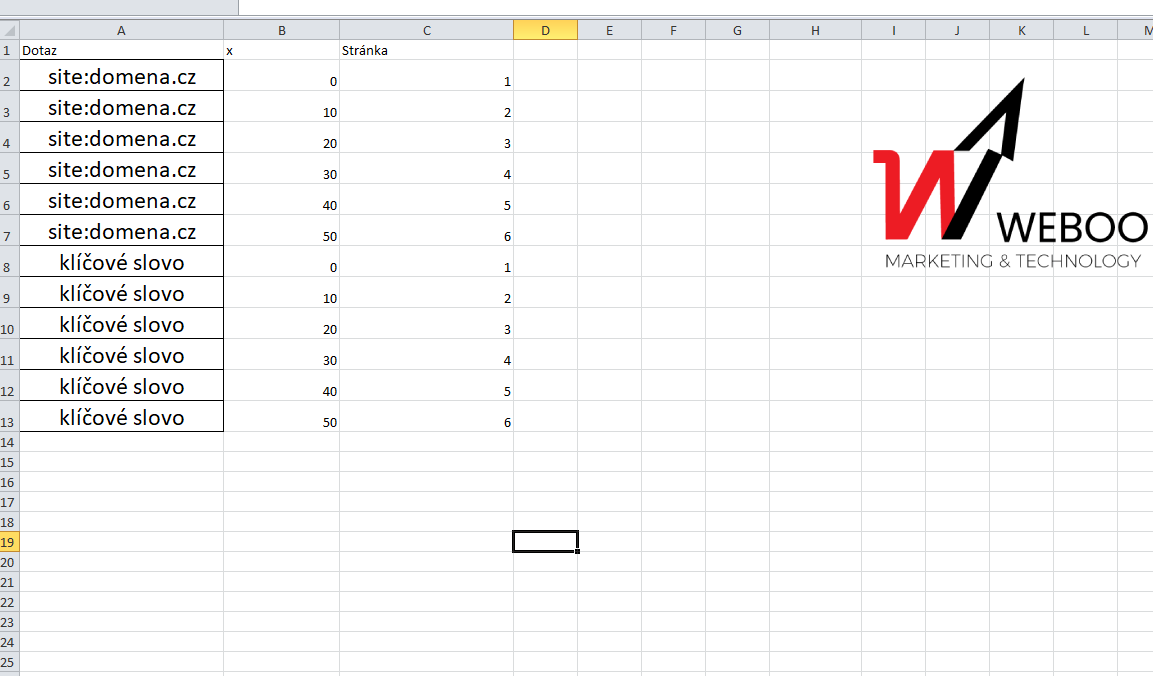
Tyhle tři sloupce si zkopírujeme (klasika klik do tabulky a CTRL + A) a můžeme se přesunout na zábavnou část 
Krok 2 – OpenRefine kouzelnictví
OpenRefine je takový namakaný Excel, který umí úplně všechno. Začátky jsou s ním trochu složité a není úplně intuitivní, ale po chvíli na něj nikdo nedá dopustit.
Postup pro začátečníky:
- Otevřeme OpenRefine
- Klik na „Clipboard“ a vložíme naše tři sloupečky
- Klik na „Next“
- Klik na „Create Project“
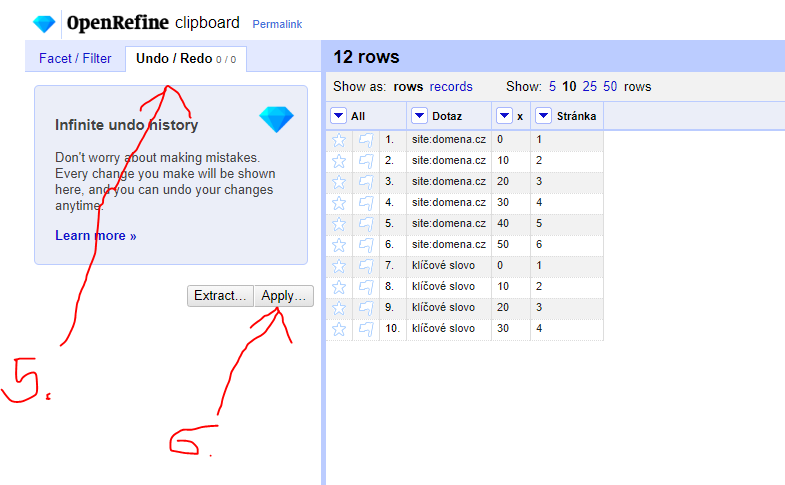
- Klik na Undo / Redo
- Klik na „Apply“
Zase pro jistotu vkládám obrázek toho, jak by to mělo vypadat.
Do prázdného místa je teď třeba vložit tento skript:
{
"op": "core/column-addition",
"description": "Create column url verze at index 1 based on column Dotaz using expression grel:value.escape('url')",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "url verze",
"columnInsertIndex": 1,
"baseColumnName": "Dotaz",
"expression": "grel:value.escape('url')",
"onError": "set-to-blank"
},
{
"op": "core/column-addition-by-fetching-urls",
"description": "Create column URL at index 2 by fetching URLs based on column url verze using expression grel:\"https://search.seznam.cz/?q=\"+ value + \"&count=10&from=\" + cells[\"x\"].value",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "URL",
"columnInsertIndex": 2,
"baseColumnName": "url verze",
"urlExpression": "grel:\"https://search.seznam.cz/?q=\"+ value + \"&count=10&from=\" + cells[\"x\"].value",
"onError": "set-to-blank",
"delay": 5000,
"cacheResponses": true,
"httpHeadersJson": [
{
"name": "authorization",
"value": ""
},
{
"name": "user-agent",
"value": "OpenRefine 3.1 [b90e413]"
},
{
"name": "accept",
"value": "*/*"
}
]
},
{
"op": "core/multivalued-cell-split",
"description": "Split multi-valued cells in column URL",
"columnName": "URL",
"keyColumnName": "Dotaz",
"mode": "separator",
"separator": "h3 class=",
"regex": true
},
{
"op": "core/fill-down",
"description": "Fill down cells in column Dotaz",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Dotaz"
},
{
"op": "core/fill-down",
"description": "Fill down cells in column Stránka",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Stránka"
},
{
"op": "core/column-addition",
"description": "Create column Titulek at index 3 based on column URL using expression grel:value.get(indexOf(value,\"<span>\")+6, indexOf(value,\"</span>\"))",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Titulek",
"columnInsertIndex": 3,
"baseColumnName": "URL",
"expression": "grel:value.get(indexOf(value,\"<span>\")+6, indexOf(value,\"</span>\"))",
"onError": "set-to-blank"
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Titulek using expression grel:value.replace(value.get(indexOf(value,\"<\"), indexOf(value,\">\")+1),'')",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Titulek",
"expression": "grel:value.replace(value.get(indexOf(value,\"<\"), indexOf(value,\">\")+1),'')",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Titulek using expression grel:value.replace(value.get(indexOf(value,\"<\"), indexOf(value,\">\")+1),'')",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Titulek",
"expression": "grel:value.replace(value.get(indexOf(value,\"<\"), indexOf(value,\">\")+1),'')",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Titulek using expression grel:value.replace(value.get(indexOf(value,\"<\"), indexOf(value,\">\")+1),'')",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Titulek",
"expression": "grel:value.replace(value.get(indexOf(value,\"<\"), indexOf(value,\">\")+1),'')",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column URL using expression grel:value.get(indexOf(value,\"href=\")+6, indexOf(value,\"><span>\")-1)",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "URL",
"expression": "grel:value.get(indexOf(value,\"href=\")+6, indexOf(value,\"><span>\")-1)",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column URL using expression grel:value.split(\"\\\"\")[0]",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "URL",
"expression": "grel:value.split(\"\\\"\")[0]",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/row-removal",
"description": "Remove rows",
"engineConfig": {
"facets": [
{
"type": "list",
"name": "x",
"expression": "value",
"columnName": "x",
"invert": true,
"selection": [],
"selectNumber": false,
"selectDateTime": false,
"selectBoolean": false,
"omitBlank": false,
"selectBlank": true,
"omitError": false,
"selectError": false
}
],
"mode": "row-based"
}
},
{
"op": "core/column-removal",
"description": "Remove column url verze",
"columnName": "url verze"
},
{
"op": "core/column-removal",
"description": "Remove column x",
"columnName": "x"
}
]
Vteřinku teď necháme OpenRefine pracovat a voilà, vyskočí na nás URL adresy. Jako bonus jsem do skriptu hodil i zobrazovaný titulek. Tedy ne titulek, který máte na stránkách nastavený, ale ten, který se reálně zobrazuje.
Výsledek tedy bude vypadat takhle:
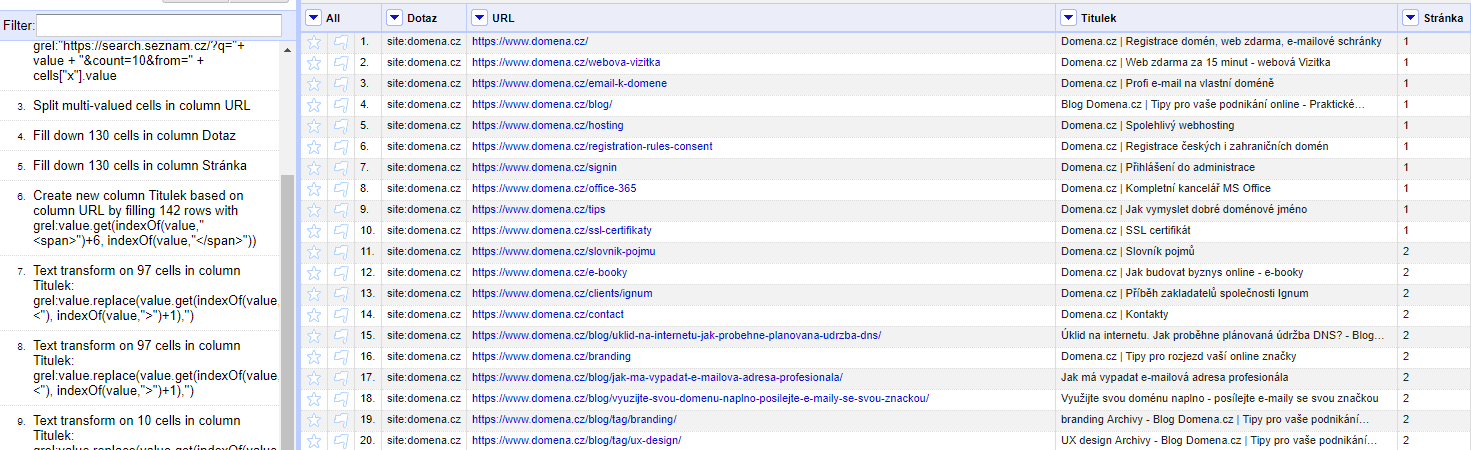
Teď už jen stačí exportovat
Co teď s tím? Všechno možné.
První si vyzkoušejte vytáhnout URL ze sitemapy. Zbytek se dozvíte se někdy v dalším článku 

Bc. ADAM TELIČKA
SEO mág Adam je kromě optimalizace pro vyhledávače šikovný textař, e-mail markeťák, linkbuilder a specialista na gramatické oříšky.
Email: Tato e-mailová adresa je chráněna před spamboty. Pro její zobrazení musíte mít povolen Javascript.
